メディア事業ベンチャーの営業部あるある。


これは僕自身実際にあった話で、おそらく、立ち上げ間もない営業部はこの状況よくあると思います。メディアのPR表記のルールって結構変わるので、タグを直張りで都度対応していたりして、WPなり管理ツールから取れない情報って意外に多いんですよね。
営業部全体の運用や、編集部とのオペレーションは、人数やメンバーのリテラシーに合わせて、ツール&ルールを変えるべきなのですが、最初のごちゃごちゃした情報を、まず整理するのって、意外に大変で時間がかかります。とりあえず使っていたPCのフォルダ整理みたいな感じです。
今回は、スクレイピングを使って、過去に出稿頂いた”PR記事を見つける”というのがお題。
スクレイピング自体は、もちろん競合の出稿状況を調べる、みたいなことから、提案に使う情報を引っ張ってくることまでできます。(が、スクレイピングにもいろいろルールがあるので、使い方は注意事項を見て自己判断でお願いします。)
今回、サイト例として僕の前職のメディア「CAMP HACK」を使わせてもらいました。
宣伝ではないですが、こういうニッチメディアは、とにかくユーザーの閲覧モチベーションが高いのと、編集部も中身に本気なので、広告の質と効果が高いです。私自身いろいろメディアタイアップを見てきたつもりですが、オススメです。出稿を考えている人は繋ぎますので是非!
注意点
既にWEB記事がいっぱいあるので、僕が改める必要はないのですが一応。
まずスクレイピング自体は違法でもなんでもありません。悪用するとサーバーに負荷がかかったり、ご迷惑がかかることがあるので、マナーを守ってやりましょうという事。
・リクエストの間隔を1秒以上開ける
・robots.txtや規約を確認し、NGページを確認する
・データの公開方法や用途に気をつける
以下のページに詳しく書いているので見てみてください。
https://qiita.com/nezuq/items/c5e827e1827e7cb29011
http://docs.pyq.jp/column/crawler.html
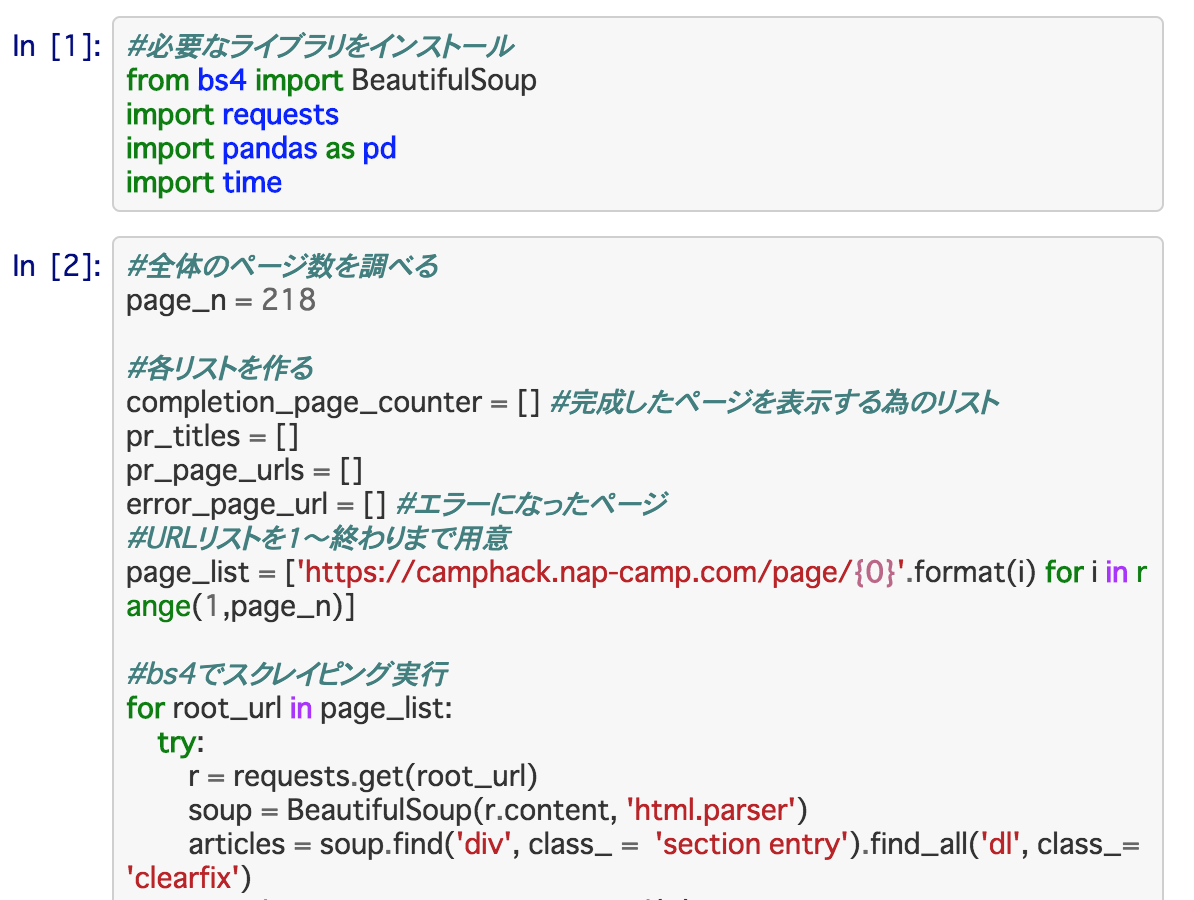
早速やってみる
PR記事を見つけるというのは、サイトによっては単純にキーワード指定で「PR」と検索すれば引っかかることもありますし、今回のようなspanタグなど特定のタグから見つけないといけないこともあります。どちらにしても、PR表記は必須なので、各サイトに合わせて変えてください。
今回の記事はスクレイピングの”ちょっと変わった使い方”を紹介することが目的なので、スクレイピング方法の詳細や、ライブラリの紹介などは別記事に譲ります。
※コードはそのままですが、出力は端折っています。
今回はjupyterを使って動かしました。javascriptを使っていて、URLは変わらないのにページが変わる、みたいなサイトはSeleniumを使ってブラウザを動かして取る必要がありますが、今回はURL指定で取ってこれたので、ライブラリbs4を使ってhtmlを分解してます。
コード内容は、単純にPR表記のspanタグがあるかないかを取ってきているのですが、エラーが出ることがあります。その時用に同じ処理をエラーページにも適用する作業を繰り返しています。
(僕は非エンジニアなので、もっと良い書き方があるかもしれませんが、営業は、とりあえず動けばOK!の精神が大切です笑)
こんな感じで、一度スクレイピングを覚えてしまうといろいろと汎用が効くと思いますので、とりあえず身の回りの作業からやってみましょう!
コメントを残す